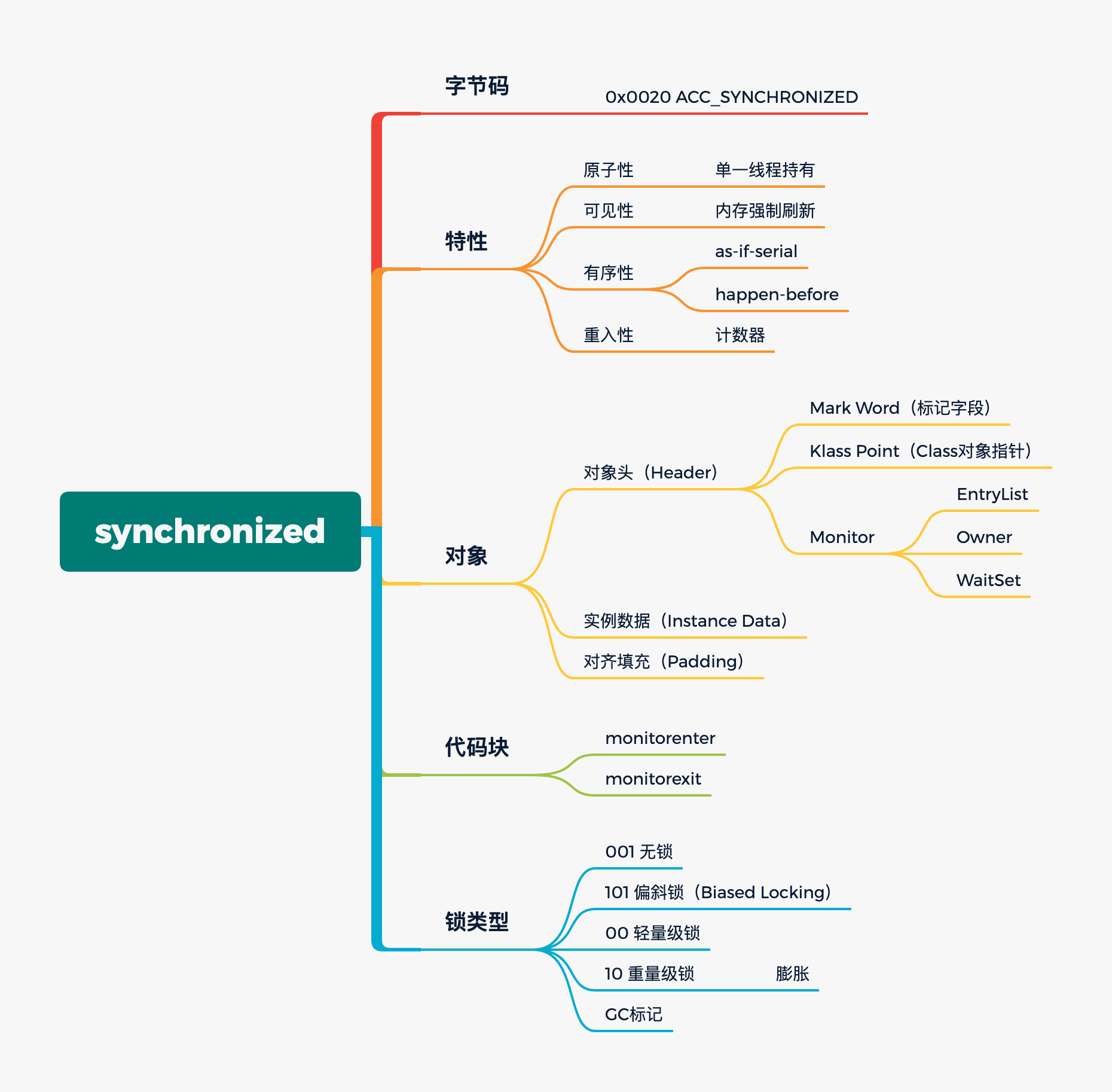
# synchronized
# 对象结构
# 对象结构介绍
 HotSpot虚拟机 markOop.cpp 中的 C++ 代码注释片段,描述了 64bits 下 mark-word 的存储状态,也就是上图的结构示意。
HotSpot虚拟机 markOop.cpp 中的 C++ 代码注释片段,描述了 64bits 下 mark-word 的存储状态,也就是上图的结构示意。
64 bits:
--------
unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) //无锁对象头
JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) //偏向锁对象头
PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
size:64 ----------------------------------------------------->| (CMS free block)
unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
2
3
4
5
6
7
8
9
10
11
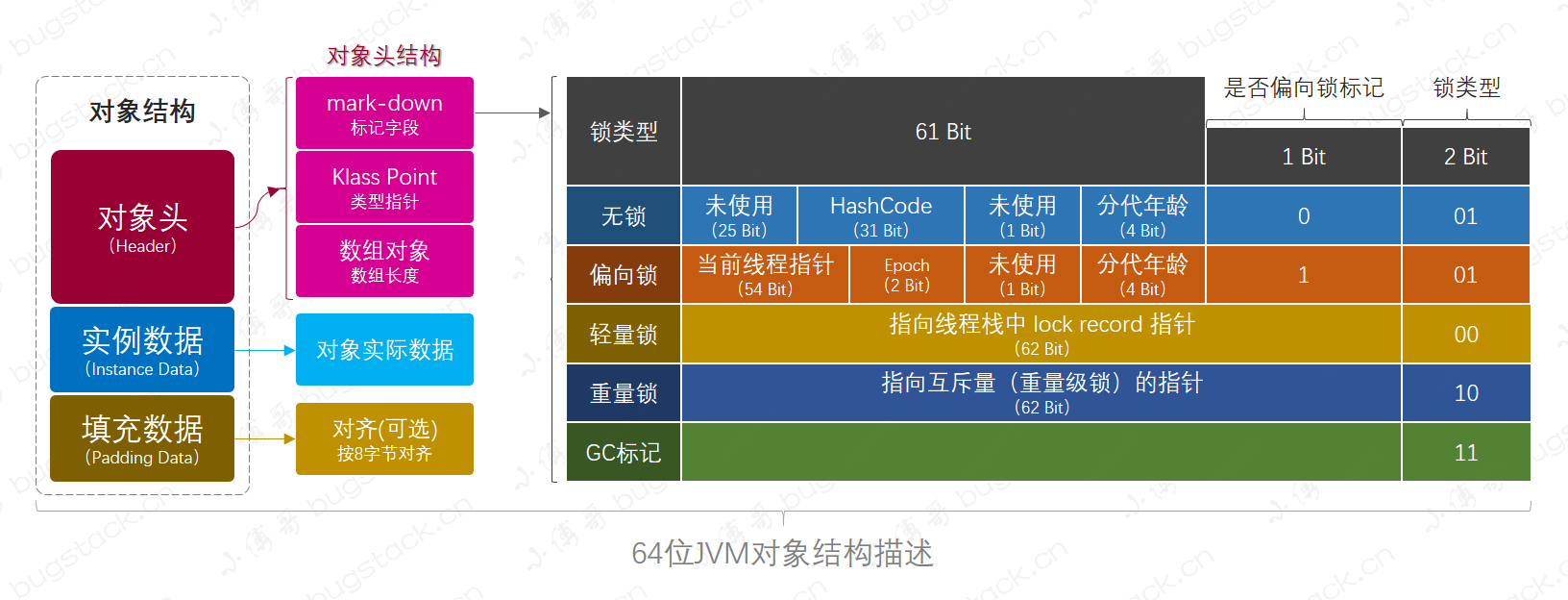
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
- mark-word:对象标记字段占8个字节,用于存储一些列的标记位,比如:哈希值、轻量级锁的标记位,偏向锁标记位、分代年龄等。
- Klass Pointer:Class对象的类型指针,Jdk1.8默认开启指针压缩后为4字节,关闭指针压缩(-XX:-UseCompressedOops)后,长度为8字节。其指向的位置是对象对应的Class对象(其对应的元数据对象)的内存地址。
- 对象实际数据:包括对象的所有成员变量,大小由各个成员变量决定,比如:byte占1个字节8比特位、int占4个字节32比特位。
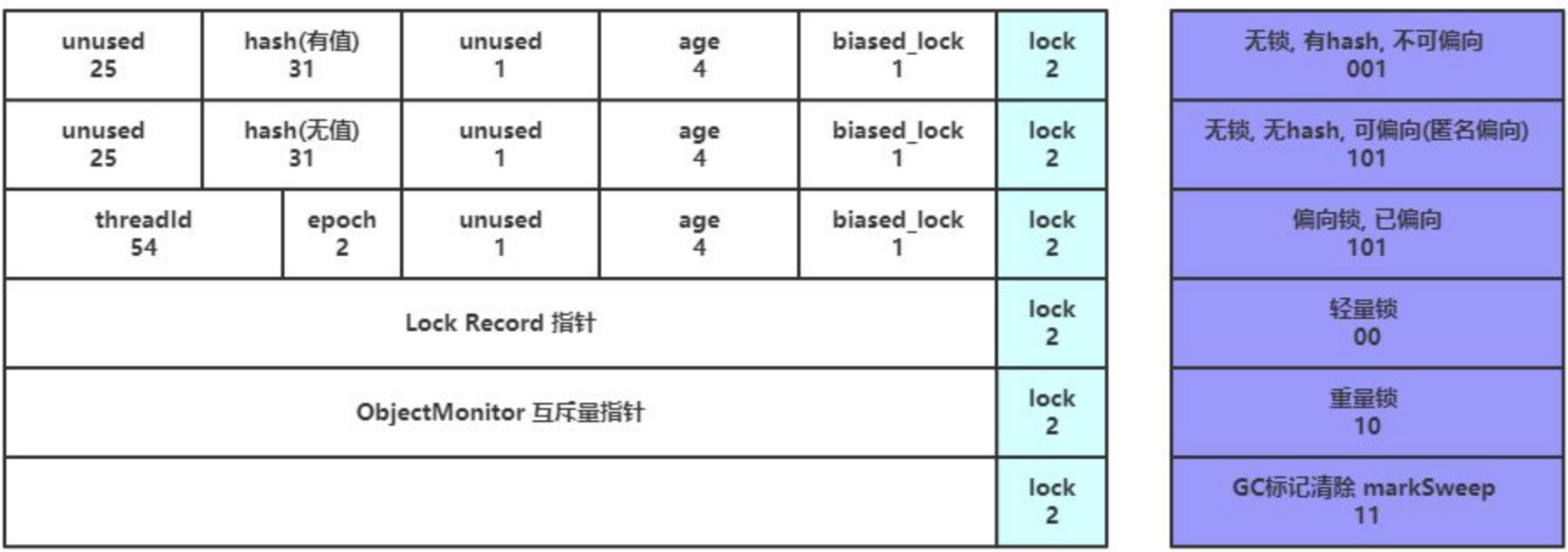
- 对齐:最后这段空间补全并非必须,仅仅为了起到占位符的作用。由于HotSpot虚拟机的内存管理系统要求对象起始地址必须是8字节的整数倍,所以对象头正好是8字节的倍数。因此当对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。 另外,在mark-word锁类型标记中,无锁,偏向锁,轻量锁,重量锁,以及GC标记,5种类中不能用2比特标记(2比特最终有4种组合00、01、10、11),所以无锁、偏向锁,前又占了一位偏向锁标记。最终:001为无锁、101为偏向锁。
# 验证对象结构
为了可以更加直观的看到对象结构,我们可以借助 openjdk 提供的 jol-core 进行打印分析。
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-cli -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-cli</artifactId>
<version>0.14</version>
</dependency>
2
3
4
5
6
测试代码
public static void main(String[] args) {
System.out.println(VM.current().details());
Object obj = new Object();
System.out.println(obj + " 十六进制哈希:" + Integer.toHexString(obj.hashCode()));
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
2
3
4
5
6
# 指针压缩开启(默认)
运行结果
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
2
3
4
5
6
7
8
9
10
11
12
13
14
15

- Object对象,总共占16字节
- 对象头占 12 个字节,其中:mark-down 占 8 字节(64bit)、Klass Point 占 4 字节
- 最后 4 字节,用于数据填充找齐
# 指针压缩关闭
在 Run-->Edit Configurations->VM Options 配置参数 -XX:-UseCompressedOops 关闭指针压缩。
运行结果
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 12 0c 53 (00000001 00010010 00001100 01010011) (1393299969)
4 4 (object header) 02 00 00 00 (00000010 00000000 00000000 00000000) (2)
8 4 (object header) 00 1c b9 1b (00000000 00011100 10111001 00011011) (465116160)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
2
3
4
5
6
7
8
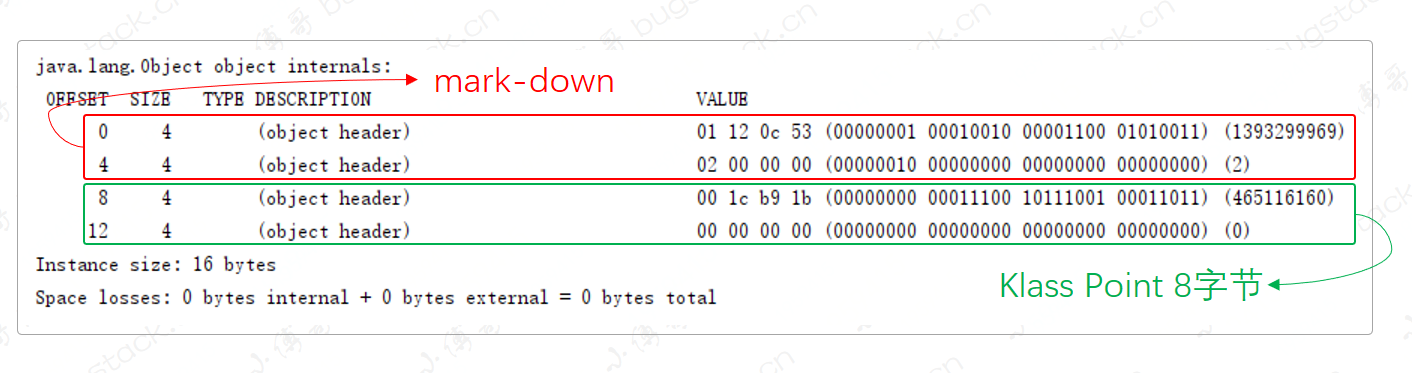
- 关闭指针压缩后,mark-word 还是占 8 字节不变。
- 重点在类型指针 Klass Point 的变化,由原来的 4 字节,现在扩增到 8 字节。
# 对象头哈希值存储验证
接下来,我们调整下测试代码,看下哈希值在对象头中具体是怎么存放的。 测试代码
public static void main(String[] args) {
System.out.println(VM.current().details());
Object obj = new Object();
System.out.println(obj + " 十六进制哈希:" + Integer.toHexString(obj.hashCode()));
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
2
3
4
5
6
- 改动不多,只是把哈希值和对象打印出来,方便我们验证对象头关于哈希值的存放结果。
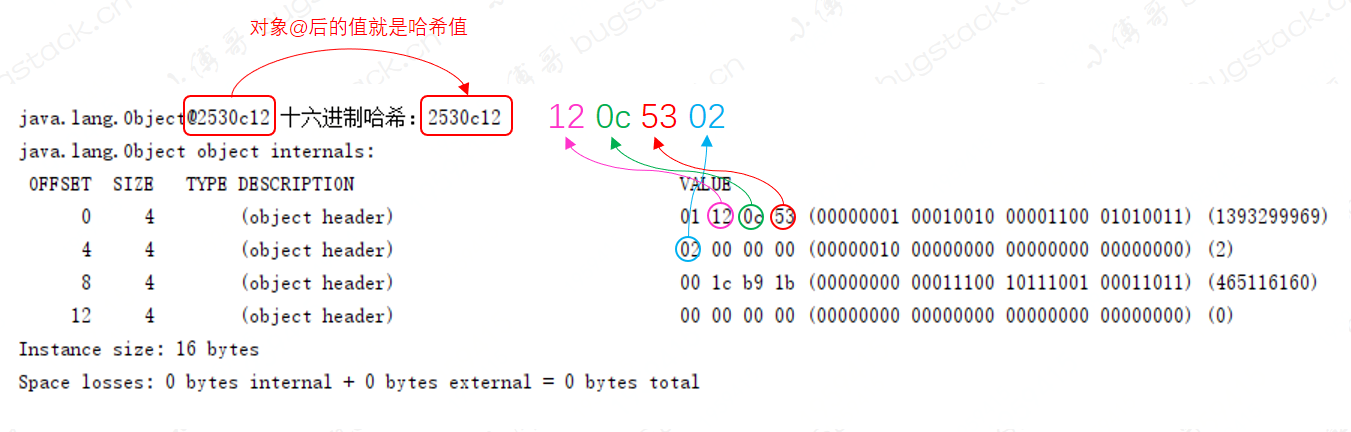
- 如图 15-3,对象的哈希值是16进制的,0x2530c12
- 在对象头哈希值存放的结果上看,也有对应的数值。只不过这个结果是倒过来的。 关于这个倒过来的问题是因为,大小端存储导致:
- Big-Endian:高位字节存放于内存的低地址端,低位字节存放于内存的高地址端
- Little-Endian:低位字节存放于内存的低地址端,高位字节存放于内存的高地址端
# mark-down结构
 如图,最右侧的 3 Bit(1 Bit标识偏向锁,2 Bit描述锁的类型)是跟锁类型和GC标记相关的,而 synchronized 的锁优化升级膨胀就是修改的这三位上的标识,来区分不同的锁类型。从而采取不同的策略来提升性能。
如图,最右侧的 3 Bit(1 Bit标识偏向锁,2 Bit描述锁的类型)是跟锁类型和GC标记相关的,而 synchronized 的锁优化升级膨胀就是修改的这三位上的标识,来区分不同的锁类型。从而采取不同的策略来提升性能。
# Monitor 对象
在HotSpot虚拟机中,monitor是由C++中ObjectMonitor实现。
synchronized 的运行机制,就是当 JVM 监测到对象在不同的竞争状况时,会自动切换到适合的锁实现,这种切换就是锁的升级、降级。
那么三种不同的 Monitor 实现,也就是常说的三种不同的锁:偏向锁(Biased Locking)、轻量级锁和重量级锁。当一个 Monitor 被某个线程持有后,它便处于锁定状态。
Monitor 主要数据结构如下:
// initialize the monitor, exception the semaphore, all other fields
// are simple integers or pointers
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录个数
_waiters = 0,
_recursions = 0; // 线程重入次数
_object = NULL; // 存储 Monitor 对象
_owner = NULL; // 持有当前线程的 owner
_WaitSet = NULL; // 处于wait状态的线程,会被加入到 _WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; // 单向列表
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- ObjectMonitor,有两个队列:_WaitSet、_EntryList,用来保存 ObjectWaiter 对象列表。
- _owner,获取 Monitor 对象的线程进入 _owner 区时, _count + 1。如果线程调用了 wait() 方法,此时会释放 Monitor 对象, _owner 恢复为空, _count - 1。同时该等待线程进入 _WaitSet 中,等待被唤醒。
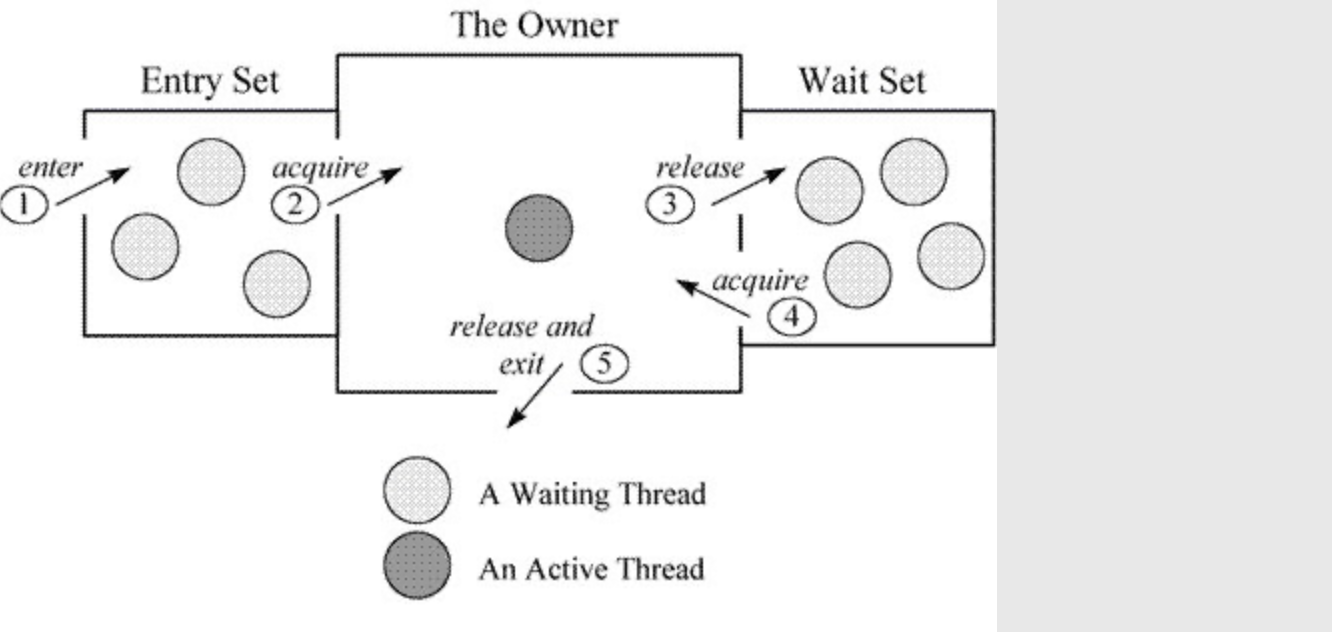 ObjectWaiter首先会进入 Entry Set等着,当线程获取到对象的monitor后进入 The Owner 区域并把monitor中的owner变量设置为当前线程,同时monitor中的计数器count加1,若线程调用wait()方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor并复位变量的值,以便其他线程进入获取对象的
ObjectWaiter首先会进入 Entry Set等着,当线程获取到对象的monitor后进入 The Owner 区域并把monitor中的owner变量设置为当前线程,同时monitor中的计数器count加1,若线程调用wait()方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor并复位变量的值,以便其他线程进入获取对象的monitor。
虽然这样的设计思路非常合理,但是在大多数应用上,每一个线程占用同步代码块的时间并不是很长,我们完全没有必要将竞争中的线程挂起然后又唤醒,并且现代CPU基本都是多核心运行的,我们可以采用一种新的思路来实现锁。
在JDK1.4.2时,引入了自旋锁(JDK6之后默认开启),它不会将处于等待状态的线程挂起,而是通过无限循环的方式,不断检测是否能够获取锁,由于单个线程占用锁的时间非常短,所以说循环次数不会太多,可能很快就能够拿到锁并运行,这就是自旋锁。当然,仅仅是在等待时间非常短的情况下,自旋锁的表现会很好,但是如果等待时间太长,由于循环是需要处理器继续运算的,所以这样只会浪费处理器资源,因此自旋锁的等待时间是有限制的,默认情况下为10次,如果失败,那么会进而采用重量级锁机制。
在JDK6之后,自旋锁得到了一次优化,自旋的次数限制不再是固定的,而是自适应变化的,比如在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行,那么这次自旋也是有可能成功的,所以会允许自旋更多次。当然,如果某个锁经常都自旋失败,那么有可能会不再采用自旋策略,而是直接使用重量级锁。
# synchronized 特性
# 原子性
- 原子性是指一个操作是不可中断的,要么全部执行成功要么全部执行失败。
private static volatile int counter = 0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
for (int i1 = 0; i1 < 10000; i1++) {
add();
}
});
thread.start();
}
// 等10个线程运行完毕
Thread.sleep(1000);
System.out.println(counter);
}
public static void add() {
counter++;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这段代码开启了 10 个线程来累加 counter,按照预期结果应该是 100000。但实际运行会发现,counter 值每次运行都小于 10000,这是因为 volatile 并不能保证原子性,所以最后的结果不会是10000。 修改方法 add(),添加 synchronized:
public static void add() {
synchronized (this) {
counter++;
}
}
2
3
4
5
这回测试结果就是:100000 了!
因为 synchronized 可以保证统一时间只有一个线程能拿到锁,进入到代码块执行。
# 反编译查看指令码
javap -v -p AtomicityTest
public static void add();
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=0
0: ldc #12 // class org/itstack/interview/AtomicityTest
2: dup
3: astore_0
4: monitorenter
5: getstatic #10 // Field counter:I
8: iconst_1
9: iadd
10: putstatic #10 // Field counter:I
13: aload_0
14: monitorexit
15: goto 23
18: astore_1
19: aload_0
20: monitorexit
21: aload_1
22: athrow
23: return
Exception table:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
同步方法
ACC_SYNCHRONIZED这是一个同步标识,对应的16进制值是 0x0020 这10个线程进入这个方法时,都会判断是否有此标识,然后开始竞争 Monitor 对象。
同步代码
- monitorenter,在判断拥有同步标识
ACC_SYNCHRONIZED抢先进入此方法的线程会优先拥有 Monitor 的 owner ,此时计数器 +1。 - monitorexit,当执行完退出后,计数器 -1,归 0 后被其他进入的线程获得。
# 可见性
我们知道volatile保证变量对所有线程的可见性。最终的效果就是在添加 volatile 的属性变量时,线程A修改值后,线程B能读取到最新的变量值 那么,synchronized 具备可见性吗,我们做个例子:
public static boolean sign = false;
public static void main(String[] args) {
Thread Thread01 = new Thread(() -> {
int i = 0;
while (!sign) {
i++;
add(i);
}
});
Thread Thread02 = new Thread(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException ignore) {
}
sign = true;
logger.info("vt.sign = true while (!sign)")
});
Thread01.start();
Thread02.start();
}
public static int add(int i) {
return i + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这是两个线程操作一个变量的例子,因为线程间对变量 sign 的不可见性,线程 Thread01 中的 while (!sign) 会一直执行,不会随着线程 Thread02 修改 sign = true 而退出循环。
现在我们给方法 add 添加 synchronized 关键字修饰,如下:
public static synchronized int add(int i) {
return i + 1;
}
2
3
添加后运行结果:
23:55:33.849 [Thread-1] INFO org.itstack.interview.VisibilityTest - vt.sign = true while (!sign)
Process finished with exit code 0
2
3
可以看到当线程 Thread02 改变变量 sign = true 后,线程 Thread01 立即退出了循环。
注意:不要在方法中添加 System.out.println() ,因为这个方法中含有 synchronized 会影响测试结果!
那么为什么添加 synchronized 也能保证变量的可见性呢?
因为:
- 线程解锁前,必须把共享变量的最新值刷新到主内存中。
- 线程加锁前,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值。
- volatile 的可见性都是通过内存屏障(Memnory Barrier)来实现的。
- synchronized 靠操作系统内核互斥锁实现,相当于 JMM 中的 lock、unlock。退出代码块时刷新变量到主内存。
# 有序性
as-if-serial,保证不管编译器和处理器为了性能优化会如何进行指令重排序,都需要保证单线程下的运行结果的正确性。也就是常说的:如果在本线程内观察,所有的操作都是有序的:如果在一个线程观察另一个线程,所有的操作都是无序的。
这里有一段双重检验锁(Double-checked Locking)的经典案例:
public class Singleton {
private Singleton() {
}
private volatile static Singleton instance;
public Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
为什么,synchronized 也有可见性的特点,还需要 volatile 关键字? 因为,synchronized 的有序性,不是 volatile 的防止指令重排序。 那如果不加 volatile 关键字可能导致的结果,就是第一个线程在初始化初始化对象,设置 instance 指向内存地址时。第二个线程进入时,有指令重排。在判断 if (instance == null) 时就会有出错的可能,因为这会可能 instance 可能还没有初始化成功。 具体解析
# 可重入性
synchronized 是可重入锁,也就是说,允许一个线程二次请求自己持有对象锁的临界资源,这种情况称为可重入锁🔒。 例子:
public class ReentryTest extends A{
public static void main(String[] args) {
ReentryTest reentry = new ReentryTest();
reentry.doA();
}
public synchronized void doA() {
System.out.println("子类方法:ReentryTest.doA() ThreadId:" + Thread.currentThread().getId());
doB();
}
private synchronized void doB() {
super.doA();
System.out.println("子类方法:ReentryTest.doB() ThreadId:" + Thread.currentThread().getId());
}
}
class A {
public synchronized void doA() {
System.out.println("父类方法:A.doA() ThreadId:" + Thread.currentThread().getId());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这段单例代码是递归调用含有 synchronized 锁的方法,从运行正常的测试结果看,并没有发生死锁。所有可以证明 synchronized 是可重入锁。
synchronized锁对象的时候有个计数器,他会记录下线程获取锁的次数,在执行完对应的代码块之后,计数器就会-1,直到计数器清零,就释放锁了。
之所以,是可以重入。是因为 synchronized 锁对象有个计数器,会随着线程获取锁后 +1 计数,当线程执行完毕后 -1,直到清零释放锁。
# 锁升级过程
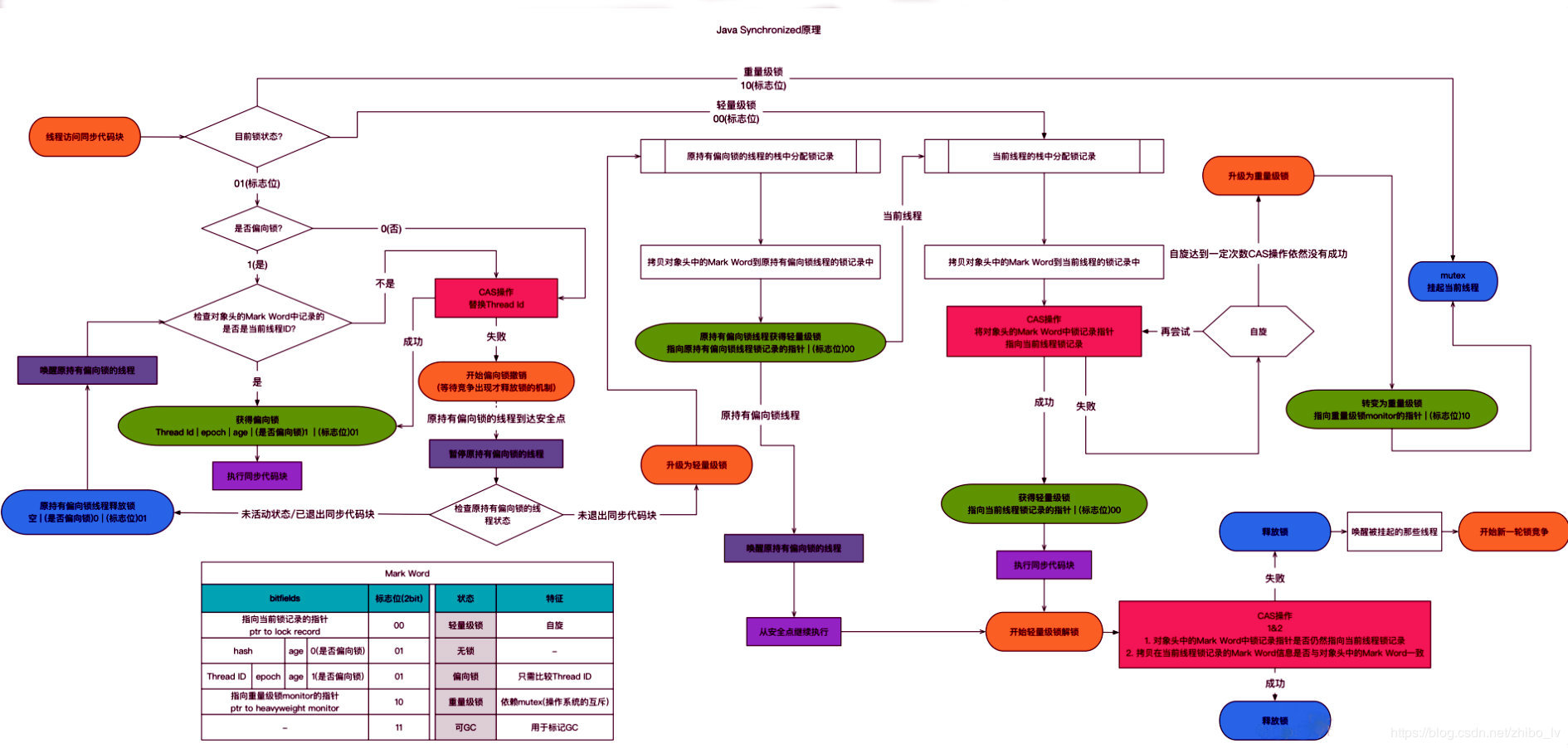 synchronized 锁有四种交替升级的状态:无锁、偏向锁、轻量级锁和重量级,这几个状态随着竞争情况逐渐升级。
synchronized 锁有四种交替升级的状态:无锁、偏向锁、轻量级锁和重量级,这几个状态随着竞争情况逐渐升级。
# 偏向锁
// NOTE: must use heavy weight monitor to handle jni monitor exit
void ObjectSynchronizer::jni_exit(oop obj, Thread* THREAD) {
TEVENT (jni_exit) ;
if (UseBiasedLocking) {
Handle h_obj(THREAD, obj);
BiasedLocking::revoke_and_rebias(h_obj, false, THREAD);
obj = h_obj();
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
ObjectMonitor* monitor = ObjectSynchronizer::inflate(THREAD, obj);
// If this thread has locked the object, exit the monitor. Note: can't use
// monitor->check(CHECK); must exit even if an exception is pending.
if (monitor->check(THREAD)) {
monitor->exit(true, THREAD);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- UseBiasedLocking 是一个偏向锁检查,1.6之后是默认开启的,1.5中是关闭的,需要手动开启参数是 XX:-UseBiasedLocking=false 偏向锁会延缓 JIT 预热进程,所以很多性能测试中会显式地关闭偏斜锁,偏斜锁并不适合所有应用场景,撤销操作(revoke)是比较重的行为,只有当存在较多不会真正竞争的 synchronized 块儿时,才能体现出明显改善。
- 值得注意的是,如果对象通过调用hashCode()方法计算过对象的一致性哈希值,那么它是不支持偏向锁的,会直接进入到轻量级锁状态,因为Hash是需要被保存的,而偏向锁的Mark Word数据结构,无法保存Hash值;如果对象已经是偏向锁状态,再去调用hashCode()方法,那么会直接将锁升级为重量级锁,并将哈希值存放在monitor(有预留位置保存)中。
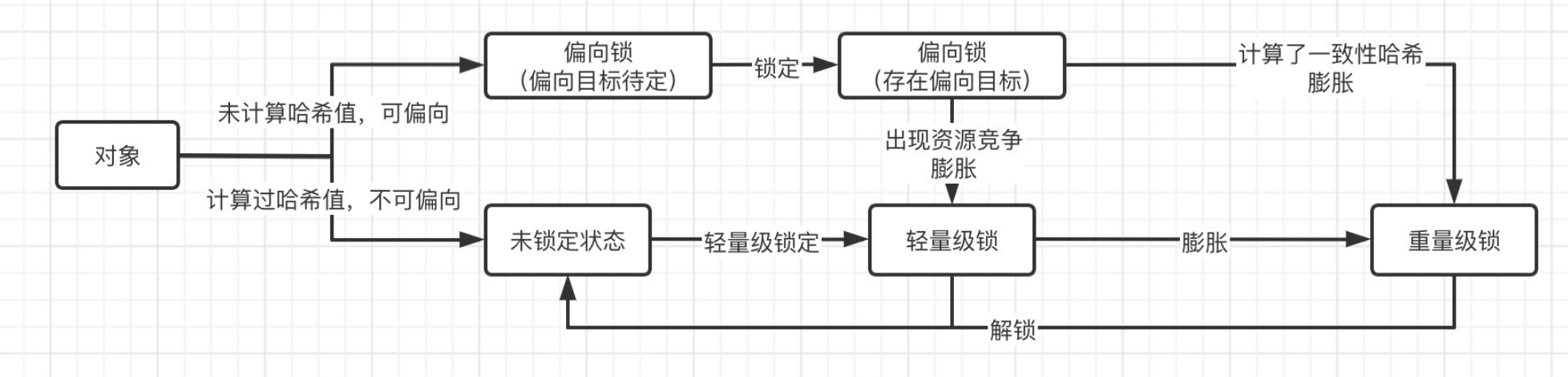
# 轻量级锁
当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),JVM虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为 Displaced Mark Word。
# 自旋锁
自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
自旋锁的默认大小是10次,可以调整:-XX:PreBlockSpin
如果自旋n次失败了,就会升级为重量级的锁。重量级的锁,在 Monitor 对象中已经介绍。
# 锁会降级吗?
之前一直了解到 Java 不会进行锁降级,但最近整理了大量的资料发现锁降级确实是会发生。
- When safepoints are used?
Below are few reasons for HotSpot JVM to initiate a safepoint:
Garbage collection pauses
Code deoptimization
Flushing code cache
Class redefinition (e.g. hot swap or instrumentation)
Biased lock revocation
Various debug operation (e.g. deadlock check or stacktrace dump)
2
3
4
5
6
7
Biased lock revocation,当 JVM 进入安全点 SafePoint (opens new window)的时候,会检查是否有闲置的 Monitor,然后试图进行降级。