# kafka
# 下载安装
# 官网下载
官网下载解压即可:https://kafka.apache.org/downloads
# 非本机访问配置
如果需要其他机器访问安装的kafka,则需要修改配置
监听端口 允许外部ip访问
# listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://0.0.0.0:9092
对外服务ip
# advertised.listeners=PLAINTEXT://your.host.name:9092
advertised.listeners=PLAINTEXT://安装的机器ip:9092
2
3
4
5
6
7
# docker下载
docker pull apache/kafka:[version] 例如:
docker pull apache/kafka:3.7.0
注意:docker 需要代理才能拉镜像,可参考本网站的docker篇章
# docker外部机器连接不上
docker容器的kafka有三种配置启动方式 详情可看 docker文档:https://github.com/apache/kafka/blob/trunk/docker/examples/README.md
- 默认配置:外部连不上
- 文件输入:提供本地配置文件,替换掉docker中默认配置
# 进去kafka容器
# 进去容器配置文件 /etc/kafka/docker/server.properties 不能编辑是只读的,并且这个修改只针对该容器,而不是apache/kafka镜像。所以要将配置文件放在宿主机。
docker exec -it kafka-container-id /bin/bash
# 将配置文件复制出宿主机
docker cp kafka-container-id:/etc/kafka/docker/server.properties /opt/kafka/docker/
# 将配置编辑如下
2
3
4
5
6
7
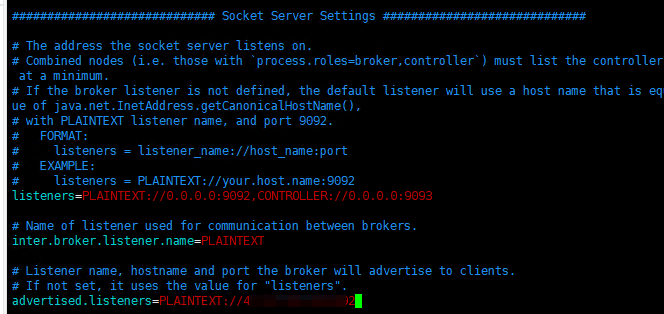
修改完配置后,将配置挂载
# docker run --volume(或简称 -v) 是 Docker 命令中用于挂载卷(volume)的选项。卷是 Docker 用来持久化和共享数据的一种机制,可以在容器之间共享数据,或者将数据持久化到主机文件系统中。使用卷可以确保即使容器被删除,数据也不会丢失。
# 将刚才修改的配置挂载进 kafka 容器中,启动后外部可以连接
docker run --volume /opt/kafka/docker/:/mnt/shared/config -p 9092:9092 apache/kafka:3.7.0
2
3
- 环境变量:
# 使用官方脚本
# 启动/退出:
// 使用zookeeper 启动
1. zookeeper
* 启动: `bin/zookeeper-server-start.sh -daemon config/zookeeper.properties`
* 关闭: `bin/zookeeper-server-stop.sh -daemon config/zookeeper.properties`
2. kafka
* 启动: `bin/kafka-server-start.sh -daemon config/server.properties`
* 关闭: `bin/kafka-server-stop.sh -daemon config/server.properties`
// 使用 KRaft启动 (bin目录下)
1. 生成集群id
./kafka-storage.sh random-uuid # 输出82vqfbdSTO2QzS_M0Su1Bw
2. 配置元数据(集群下每台机器都要配置)
./kafka-storage.sh format -t 82vqfbdSTO2QzS_M0Su1Bw -c config/kraft/server.properties
3. 启动集群
./kafka-server-start.sh -daemon ../config/kraft/server.properties # 当全部节点都出现 Kafka Server started,集群启动成功
4. 关闭集群
./kafka-server-stop.sh -c ../config/kraft/server.properties
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 主题
使用 bin/kafka-topics.sh 不传参可以查看帮助
创建主题(topic):
* 新建一个名为"Hello-Kafka"的主题: `bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Hello-Kafka`
* 新建一个名为"hello"的主题(简易版): `bin/kafka-topics.sh --create --topic hello --bootstrap-server localhost:9092`
2
删除主题(topic):
* 删除一个名为"hello"的主题(简易版): `bin/kafka-topics.sh --delete --topic hello --bootstrap-server localhost:9092`
查看主题(topic):
* 查看主题 zookeeper: `bin/kafka-topics.sh --list --zookeeper localhost:2181`
* 查看主题: `bin/kafka-topics.sh --list --bootstrap-server localhost:9092`
2
显示主题详细(topic):
* `bin/kafka-topics.sh --describe --topic hello --bootstrap-server localhost:9092`
改变主题(topic):
* 修改分区数: `bin/kafka-topics.sh --alert --topic hello --partition 5 --bootstrap-server localhost:9092`
# 收发消息
使用bin/kafka-console-producer.sh 和 bin/kafka-console-consumer.sh
# 发送消息
* 向"Hello-Kafka"发送消息: bin/kafka-console-producer.sh --topic Hello-Kafka --bootstrap-server localhost:9092
2
# 监听主题
* 监听"Hello-Kafka" : bin/kafka-console-consumer.sh --topic Hello-Kafka --bootstrap-server localhost:9092 --from-beginning #从头开始读
2
# 重置偏移量
* offset重置到头 bin/kafka-consumer-grous.sh --bootstrap-server 127.0.0.1:9092 --group 消费者组 --topic 主题 --reset-offsets --to-earliest --excute
* offset重置到尾 bin/kafka-consumer-grous.sh --bootstrap-server 127.0.0.1:9092 --group 消费者组 --topic 主题 --reset-offsets --to-latest --excute
2
# spring集成kafka
请看本站的另一个spring栏目:看这里
# kafka 概念
# 副本Replica
在创建主题时,--replication-factor 就是指定副本数量 最小为1 最大不超过节点数量
只有一个副本时,就只有主副本即主节点。 多个副本时,读写也是操作主节点,从副本(从节点)只用于备份主节点数据。
当主节点挂掉时,从节点顶上成为主节点。
* 新建一个名为"Hello-Kafka"的主题: `bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Hello-Kafka`
# 多副本架构
# 基本概念
主题(Topic):Kafka中的消息是按主题组织的,每个主题可以看作是一类消息的集合。
分区(Partition):每个主题可以分为多个分区,分区是消息存储和读取的基本单位。分区使得消息可以并行处理。
副本(Replica):每个分区可以有多个副本,每个副本存储相同的数据。副本是Kafka高可用性的基础。
领导者副本(Leader Replica):每个分区有一个领导者副本,负责处理所有的读写请求。
跟随者副本(Follower Replica):其他副本称为跟随者副本,它们从领导者副本中复制数据,确保数据的一致性。
# 1. ISR (In-Sync Replicas)
ISR(In-Sync Replicas)指的是一个分区中与Leader保持同步的副本集合。ISR确保数据的一致性和可靠性。当一个分区的Leader接收到一条新的消息时,这条消息会被同步到ISR中的所有副本。只有在所有ISR副本都确认接收到这条消息后,消息才会被认为是已提交的。ISR集合中的副本都可以在Leader失效时被选举为新的Leader。
# 2. LEO (Log End Offset)
LEO(Log End Offset)是每个副本的一个重要属性,它表示这个副本日志中的下一条消息的Offset。换句话说,LEO是日志中当前最新消息的Offset + 1。LEO用于跟踪副本日志的末尾位置,并帮助判断副本之间的同步状态。
# 3. HW (High Watermark)
HW(High Watermark)是Leader副本的一个属性,它表示所有ISR副本都已确认的最新消息的Offset。消费者只能读取到HW之前的消息,这确保了消费者只看到已经完全同步并确认的消息。HW的存在确保了数据的一致性,即消费者不会读取到可能丢失或未同步完成的消息。
这些概念的关系
Leader和Follower:每个分区有一个Leader和多个Follower。Leader处理所有的读写请求,Follower从Leader同步数据。
ISR集合:ISR集合包括Leader和所有与Leader保持同步的Follower。只有在ISR中的副本才能被选为新的Leader。
LEO:LEO表示副本日志的末尾位置。Leader和Follower都有自己的LEO。Leader的LEO通常是最新的,而Follower的LEO会落后一些,直到它们完成同步。
HW:HW由Leader管理,表示所有ISR副本都已确认的消息的Offset。消费者只能读取到HW之前的消息。
举例说明
假设有一个分区P,它有一个Leader L和两个Follower F1和F2。
初始状态下,L、F1和F2都是ISR的一部分,且它们的LEO相同,假设是10。
当Producer写入一条新消息M时,消息M的Offset是10,L的LEO更新为11。
L将消息M同步到F1和F2,F1和F2的LEO分别更新为11。
当L确认F1和F2都已同步消息M后,L更新HW为11。
消费者读取消息时,只能读取到Offset 11之前的消息。
# 多副本架构
Kafka的多副本架构主要包括以下几个方面:
副本分布:每个分区的副本分布在不同的Kafka Broker上,以实现容错和高可用性。如果一个Broker故障,分区的副本仍然可以在其他Broker上访问。
数据复制:领导者副本负责处理写入请求,并将数据复制到所有跟随者副本。复制过程是异步的,但可以通过配置确保数据的一致性(如设置acks=all)。
故障恢复:当领导者副本失效时,Kafka会自动选举一个新的领导者副本。选举过程确保最小化数据丢失和服务中断。
ISR(In-Sync Replicas):ISR是指与领导者副本保持同步的副本集合。只有在ISR中的副本才能被选举为新的领导者副本,以确保数据的一致性和可靠性。
分区和副本管理:Kafka使用ZooKeeper来管理分区的元数据和副本状态。ZooKeeper帮助协调副本的分布和领导者的选举。
# 优势
高可用性:通过多副本机制,即使某个Broker失效,数据仍然可以通过其他副本访问。 数据持久性:多副本确保数据不会因单点故障而丢失。 负载均衡:多个副本可以分散在不同的Broker上,均衡负载,提高整体性能。
# kafka事件数据的储存
# 数据文件保存
查看kafka的配置文件: server.properties 之 log.dirs kafka的所有事件都是以日志文件的方式来保存的。格式 topicId-partitionId 例如 : test-topic-0 000000000000000000000000.index 消息索引文件 000000000000000000000000.log 消息数据文件 000000000000000000000000.timeindex 消息的时间戳索引文件 000000000000000000000001.snapshot 快照文件,生产者发生故障或者重启时能够恢复并继续之前的操作 leader-epoch-checkpoint 记录每个分区当前领导者的epoch以及领导者开始写入消息时的起始偏移量 partition.metadata 存储关于特定分区的元数据信息
# consumer_offsets
作用
__consumer_offsets是一个特殊的内部主题,用于存储消费者组的偏移量信息。主要作用是记录每个消费者组中消费者的偏移量,确保消费者发生故障或重启时能够从上次提交的偏移量继续消费,避免数据丢失或重复消费。结构和分区 分区数:
__consumer_offsets主题默认有 50 个分区。这是为了支持高并发和大规模的消费者组。 键和值:每条记录的键是一个由消费者组 ID、主题和分区组成的复合键;值是消费者的偏移量和元数据(如提交的时间戳)。记录格式 键(Key): 消费者组 ID:消费者组的唯一标识符。 主题:消费者正在消费的主题。 分区:消费者正在消费的主题分区。
值(Value): 偏移量:消费者在该分区上提交的最新偏移量。 元数据:一些额外的信息,如提交的时间戳。
- 示例
假设有一个消费者组 ID 为 group1,正在消费主题 topic1 的分区 partition0,当前偏移量为 100。在
__consumer_offsets主题中,可能存储的记录如下:
键: 消费者组 ID:group1 主题:topic1 分区:partition0
值: 偏移量:100 元数据:如时间戳 1620000000000
- 读取和监控
__consumer_offsets可以使用 Kafka 提供的工具来查看和监控__consumer_offsets主题的数据。例如,可以使用 kafka-consumer-groups.sh 工具来查看消费者组的偏移量信息。
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group group1 --describe
# group topic partition current-offset log-end-offset lag
group1 test-topic 0 10 15 5
消费组 主题 分区号 当前分区消费者offset 当前分区生产者offset 可读取消息数
2
3
4
5
这个命令将显示消费者组 group1 在各个分区上的偏移量、日志末尾偏移量以及滞后量。
内部机制 当消费者提交偏移量时,Kafka 会将该信息写入到
__consumer_offsets主题中。提交过程如下:
消费者消费消息:消费者从主题的某个分区消费消息。 提交偏移量:消费者定期提交消费到的偏移量到__consumer_offsets主题。 写入日志:提交的偏移量作为一条记录写入__consumer_offsets主题的相应分区。 从偏移量恢复:如果消费者发生故障或重新启动,它将从__consumer_offsets主题中读取最后一次提交的偏移量,继续消费。数据保留
__consumer_offsets主题的数据保留策略通常设置为较长的时间,以确保可以在较长时间内恢复消费者的状态。可以通过以下参数配置: offsets.retention.minutes:指定偏移量保留的时间,默认是 7 天。 offsets.retention.check.interval.ms:指定检查过期偏移量的间隔时间。 配置示例 在 Kafka 配置文件(server.properties)中,可以配置这些参数:
offsets.retention.minutes=10080 # 7 天
offsets.retention.check.interval.ms=600000 # 10 分钟
2
- 总结
__consumer_offsets主题是 Kafka 用于管理消费者组偏移量的核心组件。它确保消费者能够从故障中恢复,并避免数据丢失或重复消费。通过理解其工作机制和配置选项,可以更好地管理和监控 Kafka 消费者组的行为。
# kafka集群搭建
# zookeeper
# 配置非本机访问配置
如果需要其他机器访问安装的kafka,则需要修改配置
# The id of the broker. This must be set to a unique integer for each broker. broker id
broker.id=1
# 监听端口 允许外部ip访问
# listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://0.0.0.0:9092
#对外服务ip
# advertised.listeners=PLAINTEXT://your.host.name:9092
advertised.listeners=PLAINTEXT://安装的机器ip:9092
#日志文件目录
log.dirs=/tmp/kafka-logs-01
2
3
4
5
6
7
8
9
10
11
12
13
14
# 启动zookeeper
/ 使用zookeeper 启动
1. zookeeper
* 启动: `bin/zookeeper-server-start.sh -daemon config/zookeeper.properties`
* 关闭: `bin/zookeeper-server-stop.sh -daemon config/zookeeper.properties`
2. kafka
* 启动: `bin/kafka-server-start.sh -daemon config/server.properties`
* 关闭: `bin/kafka-server-stop.sh -daemon config/server.properties`
2
3
4
5
6
7
# Kraft
zookeeper 使用普通方式搭建,那KRaft就用docker吧。 先将容器的配置文件复制一份,参考这里
drwxr-xr-x 2 root root 31 Jul 30 23:04 kafka01
drwxr-xr-x 2 root root 31 Jul 30 23:05 kafka02
drwxr-xr-x 2 root root 31 Jul 30 23:05 kafka03
2
3
主要改配置如下
node.id=1
process.roles=broker,controller
listeners=PLAINTEXT://kafka-01:9092,CONTROLLER://kafka-01:9093
controller.quorum.voters=1@kafka-01:9093,2@kafka-02:9093,3@kafka-03:9093
log.dirs=/var/lib/kafka/data
metadata.log.dir=/var/lib/kafka/meta
node.id=2
process.roles=broker,controller
listeners=PLAINTEXT://kafka-02:9092,CONTROLLER://kafka-02:9093
controller.quorum.voters=1@kafka-01:9093,2@kafka-02:9093,3@kafka-03:9093
log.dirs=/var/lib/kafka/data
metadata.log.dir=/var/lib/kafka/meta
node.id=3
process.roles=broker,controller
listeners=PLAINTEXT://kafka-03:9092,CONTROLLER://kafka-03:9093
controller.quorum.voters=1@kafka-01:9093,2@kafka-02:9093,3@kafka-03:9093
log.dirs=/var/lib/kafka/data
metadata.log.dir=/var/lib/kafka/meta
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
然后启动容器
# 创建网络
docker network create kafka-network
# 启动kafka 挂载配置文件
docker run -d --name kafka-01 --hostname kafka-01 --network kafka-network -p 9092:9092 -p9093:9093 --volume /opt/kafka/docker/kafka01/:/mnt/shared/config apache/kafka:3.7.0
docker run -d --name kafka-02 --hostname kafka-02 --network kafka-network -p 9094:9092 -p9095:9093 --volume /opt/kafka/docker/kafka02/:/mnt/shared/config apache/kafka:3.7.0
docker run -d --name kafka-03 --hostname kafka-03 --network kafka-network -p 9096:9092 -p9097:9093 --volume /opt/kafka/docker/kafka03/:/mnt/shared/config apache/kafka:3.7.0
# 然后查看网络
docker network inspect kafka-network
# 输出
[
{
"Name": "kafka-network",
"Id": "f50de029ae30cb0d0603eb148663f3df92c6c0a03f1a911523ea94740fb9b33b",
"Created": "2024-07-30T22:31:46.343318515+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"6b77aad291275004b6dd17fe1c0e492996f3dd21751070faee25634c8be8d5e7": {
"Name": "kafka-01",
"EndpointID": "3982d469af589fd3eae769d55e7f2c72a09433dcd4ecfdcbf29acc7be7af5819",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
},
"86a729a8011075345e44d84e5276858ebeb7c45b855df74f649e6608e2a0ff29": {
"Name": "kafka-02",
"EndpointID": "d5bd650d88730f22f89bff513ab44a6d116e4fce4793e0800a1f8f5c45a5f1ef",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
},
"f894a3511b1756dff1fd05a883df8ca79fe53693ed9c1c8d908b7085ecf56d87": {
"Name": "kafka-03",
"EndpointID": "c3d2314b241696505632ca3d6a7bddf5dd08ecf978eea2c0406dba99cd525c3b",
"MacAddress": "02:42:ac:12:00:04",
"IPv4Address": "172.18.0.4/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
这种情况是正常启动,集群搭建完毕
题外话: 我这三个容器启动后一分钟自动退出,使用
docker logs kafka-01查看日志,发现报错找不到主机 kafka-02 kafka-03。 开始排查:
- 进入容器:docker exec -it --user root kafka-01 bash
- 查看网络:ping kafka-02 ,发现网络不通
- 利用上文的docker network inspect kafka-network 输出的Containers,查看其他容器的ip:kafka-02 172.18.0.3
- 查看网络:ping 172.18.0.3 发现网络畅通,得知是dns解析问题。不知道docker是怎么处理的。
- 自行写入hosts文件: * docker exec -it --user root kafka-01 bash * echo "172.18.0.2 kafka-01" >> /etc/hosts echo "172.18.0.3 kafka-02" >> /etc/hosts echo "172.18.0.4 kafka-03" >> /etc/hosts
- 再ping kafka-02,网络正常。后续排查docker的域名解析再更新